After a WCS update to v.2.0.239-5.2.1914 we experienced that both our Flashphoner EC2 instances became unresponsive after a several hours. Streams were not handled anymore, publishers' sessions were interrupted and REST API access timed out.
This happened both on a m5.xlarge (4vCPU, 16GB) and a c5.xlarge (4vCPU, 8GB) instance after the upgrade and has never happened before. We've had issues regarding insanely large log files (see previous topic) and thus running out of disk space but that was fixed by setting ice_tcp_transport = true.
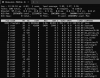
CPU on both instances was running at close to 400% (4 x 100%) at a certain point and presumably not because of high traffic / usage. Normally the m5 instance does not exceed 30% (out of 100%) CPU but after the upgrade suddenly increases out of nowhere to 100% in just a few minutes.
We've found that changing the default heap setting fixed this (no issues since changing it). It is strange however that this is suddenly an issue while it has not been an issue for 4 years since we've first started using Flashphoner (even with the 4GB c5.xlarge instance).
Default setting in wcs-core.properties:
-Xmx1024M
Changed to:
-Xmx8g -Xms8g
Which is half the memory of the m5 instance.
So far no high cpu issues occurred but apparently something in WCS's behaviour has changed that made this an issue. Also it's strange that this heap setting is not automatically set right at default when installing from the Flashphoner template on Amazon. Anyway, we hope that the increase in heap was indeed the fix to this problem.
This happened both on a m5.xlarge (4vCPU, 16GB) and a c5.xlarge (4vCPU, 8GB) instance after the upgrade and has never happened before. We've had issues regarding insanely large log files (see previous topic) and thus running out of disk space but that was fixed by setting ice_tcp_transport = true.
CPU on both instances was running at close to 400% (4 x 100%) at a certain point and presumably not because of high traffic / usage. Normally the m5 instance does not exceed 30% (out of 100%) CPU but after the upgrade suddenly increases out of nowhere to 100% in just a few minutes.
We've found that changing the default heap setting fixed this (no issues since changing it). It is strange however that this is suddenly an issue while it has not been an issue for 4 years since we've first started using Flashphoner (even with the 4GB c5.xlarge instance).
Default setting in wcs-core.properties:
-Xmx1024M
Changed to:
-Xmx8g -Xms8g
Which is half the memory of the m5 instance.
So far no high cpu issues occurred but apparently something in WCS's behaviour has changed that made this an issue. Also it's strange that this heap setting is not automatically set right at default when installing from the Flashphoner template on Amazon. Anyway, we hope that the increase in heap was indeed the fix to this problem.
Attachments
-
 99.2 KB Views: 278
99.2 KB Views: 278 -
 61.4 KB Views: 286
61.4 KB Views: 286